JDK8-Stream使用
前言
JDK8,作为目前全球最多Java程序使用的JDK版本, Oracle 公司于 2014 年 3 月 18 日发布 以来,已经过去了快8年了,JDK8依旧是目前最稳定的Java 版本。
但是你确定会使用JDK8的新特性?
这里就来说说JDK8的Stream。
Stream是JDK8中的全新特性,Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
Stream中文翻译过来叫做流,顾名思义就是以类似于输出方式来进行的函数。Stream目前主要应用于列表、集合中。通过对列表、集合获取对应的流来进行各种操作(比如过滤操作等)。
对于Java 7来说stream完全是个陌生东西,stream并不是某种数据结构,它只是数据源的一种视图。这里的数据源可以是一个数组,Java容器或I/O channel等。正因如此要得到一个stream通常不会手动创建,而是调用对应的工具方法,比如:
- 调用
Collection.stream()或者Collection.parallelStream()方法 - 调用
Arrays.stream(T[] array)方法
Stream与Collections的区别
虽然大部分情况下stream是容器调用Collection.stream()方法得到的,但stream和collections有以下不同:
- 无存储。stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。
- 为函数式编程而生。对stream的任何修改都不会修改背后的数据源,比如对stream执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新stream。
- 惰式执行。stream上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
- 可消费性。stream只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
Stream使用
创建Stream
我们可以通过4中方式来创建一个Stream:
通过一个集合来创建 对应Stream:
# 存在一个List<User> userList Stream<User> stream = userList.stream();通过一个数组创建Stream:
int[] arr = new int[]{1,2,5,7}; IntStream intStream = Arrays.stream(arr);这里的IntStream和Stream
是一样的。 通过Stream.of方法:
Stream<String> stream = Stream.of("1","4","8");利用迭代器创建一个无线长度的流:
// 每隔5个数取一个,从0开始,限制5个数 Stream.iterate(0,t->t+5).limit(5).forEach(System.out::println); // 取随机0-1浮点数 Stream.generate(Math::random).limit(5).forEach(System.out::println);
目前常见的stream接口继承关系如图:
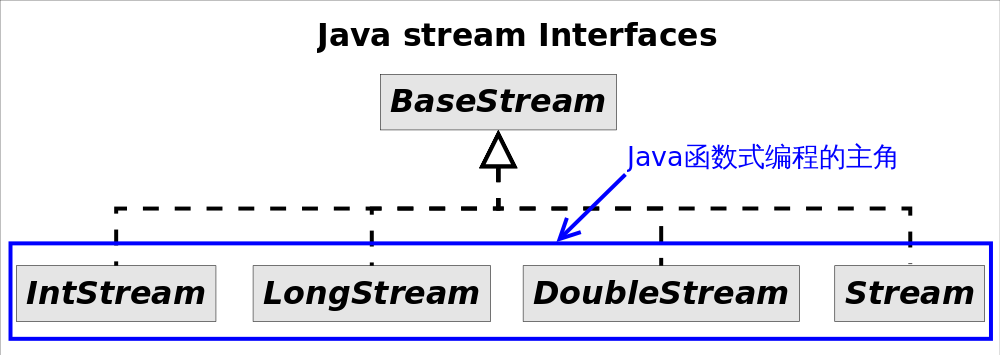
stream接口继承自BaseStream,其中IntStream, LongStream, DoubleStream对应三种基本类型(int, long, double,注意不是包装类型),Stream对应所有剩余类型的stream视图。为不同数据类型设置不同stream接口,可以有下好处:1.提高性能,2.增加特定接口函数。
操作Stream
对于某个指定的Stream,我们可以对其进行操作从而达到对其原集合进行操作或者 输出对于新内容。
筛选操作
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 10, 20, 15, 19, 54, 64, 24, 12, 48, 34, 100);
// 筛选出大于50的数,打印出来
list.stream().filter(item->item>50).forEach(System.out::println);
其中filter是Stream操作的重要方法,它是一个过滤器,它接受一个判断函数(这里使用JDK8 Lambda匿名函数)。它将其函数作用于Stream中每个元素,输出为True则保留,输出为False则抛弃。
list.stream().limit(5).forEach(System.out::println);
limit接受一个数值,表示只获取对应数值的数据。
list.stream().distinct().forEach(System.out::println);
distinct 顾名思义,就是数据结果去重操作。
处理操作
Stream可以使用其map进行处理其中的数据。
List<String> list = Arrays.asList("zaq","qwre","fgh","yyds");
Stream<String> stream = list.stream();
// 将所有值以大写打印输出
stream.map(str -> str.toUpperCase()).forEach(System.out::println);
Stream<User> userStream = userList.stream();
// 获取到每个User的年级组成Stream
Stream<Integer> ageStream = userStream.map(User::getAge);
Map 函数会将其内的匿名函数应用到Stream中每个数据,然后输出为新的Stream,常常用来进行处理Stream,并生成新的Stream。
排序操作
Stream主要使用sorted来进行排序操作。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 10, 20, 15, 19, 54, 64, 24, 12, 48, 34, 100);
// 普通自然排序
list.stream().sorted().forEach(System.out::println);
// 对象排序,指定其comparable
Stream<User> userStream = userList.stream();
userStream.sorted((user1,user2) -> Integer.compare(user1.getAge,user2.getAge)).forEach(System.out::println);
判断操作
除了使用filter来进行判断筛选之外,也可以使用allMatch`anyMatch`来进行判断操作。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 10, 20, 15, 19, 54, 64, 24, 12, 48, 34, 100);
boolean allMatch = list.stream().allMatch(item -> item > 20);
查询操作
Stream中有些函数可以进行查询到指定元素。
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 10, 20, 15, 19, 54, 64, 24, 12, 48, 34, 100);
// 查询到列表中最大的数
Optional<Integer> max = list.stream().max(Integer::compare);
System.out.println(max.get());
// 查询到大于50 的元素数量
long count = list.stream().filter(item -> item > 50).count();
其中Optional是(一个)值的容器,使用它可以避免null值的麻烦。
返回List操作
上述操作都是返回的Stream或者Optional等类型,如果想要将其结果返回为List,只需要collect函数操作,它将其Stream返回为一个List集合或者Set集合。
// 返回List
List<Integer> integerList = list.stream().collect(Collectors.toList());
// 返回Set
Set<Integer> integerSet = list.stream()..collect(Collectors.toSet());
Stream进阶
接下来详细讲解下Stream的进阶玩法以及思路:
Stream操作解析
对stream的操作分为为两类,**中间操作(intermediate operations)和结束操作(terminal operations)**,二者特点是:
- 中间操作总是会惰式执行,调用中间操作只会生成一个标记了该操作的新stream,仅此而已。
- 结束操作会触发实际计算,计算发生时会把所有中间操作积攒的操作以pipeline的方式执行,这样可以减少迭代次数。计算完成之后stream就会失效。
如果你熟悉Apache Spark RDD,对stream的这个特点应该不陌生。
下表汇总了Stream接口的部分常见方法的类型:
| 操作类型 | 接口方法 |
|---|---|
| 中间操作 | concat() distinct() filter() flatMap() limit() map() peek() skip() sorted() parallel() sequential() unordered() |
| 结束操作 | allMatch() anyMatch() collect() count() findAny() findFirst() forEach() forEachOrdered() max() min() noneMatch() reduce() toArray() |
当然区分中间操作和结束操作最简单的方法,就是看方法的返回值,返回值为stream的大都是中间操作,否则是结束操作。
约规操作
规约操作(reduction operation)又被称作折叠操作(fold),是通过某个连接动作将所有元素汇总成一个汇总结果的过程。元素求和、求最大值或最小值、求出元素总个数、将所有元素转换成一个列表或集合,都属于规约操作。
而在Stream类库有两个通用的规约操作reduce()和collect(),也有一些为简化书写而设计的专用规约操作,比如sum()、max()、min()、count()等。
Reduce
reduce操作可以实现从Stream一组元素中生成一个值,sum()、max()、min()、count()等都是reduce操作,将他们单独设为函数只是因为常用。
简而言之reduce就是将其Stream中每个元素都依次应用上指定的函数 , 最后返回结果。
reduce()的方法定义有三种形式:
Optional<T> reduce(BinaryOperator<T> accumulator)T reduce(T identity, BinaryOperator<T> accumulator)<U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
其中identity是初始值,常用于求和中, accumulator 是执行的 函数,而combiner则是多个结果合并方式函数。reduce()最常用的场景就是从一堆值中生成一个值。
Stream<String> stream = Stream.of("I", "love", "you", "too");
// 通过执行依次对比函数,找到最大的元素
Optional<String> longest = stream.reduce((s1, s2) -> s1.length()>=s2.length() ? s1 : s2);
//Optional<String> longest = stream.max((s1, s2) -> s1.length()-s2.length());
System.out.println(longest.get());
对于求和操作,我们也可以使用map()和sum(),但其实reduce也可以:
// 求单词长度之和
Stream<String> stream = Stream.of("I", "love", "you", "too");
Integer lengthSum = stream.reduce(0, // 初始值 // (1)
(sum, str) -> sum+str.length(), // 累加器 // (2)
(a, b) -> a+b); // 部分和拼接器,并行执行时才会用到 // (3)
// int lengthSum = stream.mapToInt(str -> str.length()).sum();
System.out.println(lengthSum);
这里由于Stream中的元素为String类型,而求和结果需要Integer类型,所以我们在使用length获取长度。
它的解析图:
collect
相比于reduce函数擅长生成一个值,collect则是生成一个集合或者Map对象。同时collect()也是Stream接口方法中最灵活的一个,学会它才算真正入门Java函数式编程。
// 将Stream转换成容器或Map
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(Collectors.toList()); // (1)
Set<String> set = stream.collect(Collectors.toSet()); // (2)
Map<String, Integer> map = stream.collect(Collectors.toMap(Function.identity(), String::length)); // (3)
这里面的Function.identity() 是Java 函数类 Function的一个方法,它返回一个输出跟输入一样的Lambda表达式对象,等价于形如t -> t形式的Lambda表达式,即不处理数据返回原内容。
当然对于上述只是生成普通的List 和Set类型的集合。大多数情况下我们使用的是ArrayList或者HashSet、HashMap这等实际集合类型。
// 使用toCollection()指定规约容器的类型
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));
除了输出集合对象以外,collect中也可以用来生成拼接字符串:
// 使用Collectors.joining()拼接字符串
Stream<String> stream = Stream.of("I", "love", "you");
//String joined = stream.collect(Collectors.joining());// "Iloveyou"
//String joined = stream.collect(Collectors.joining(","));// "I,love,you"
String joined = stream.collect(Collectors.joining(",", "{", "}"));// "{I,love,you}"
方法引用
从上面可以看见像”xxx::xxx”语句,其实这时JDK8中的方法引用。
诸如String::length的语法形式叫做方法引用(method references),这种语法用来替代某些特定形式Lambda表达式。如果Lambda表达式的全部内容就是调用一个已有的方法,那么可以用方法引用来替代Lambda表达式。方法引用可以细分为四类:
| 方法引用类别 | 举例 |
|---|---|
| 引用静态方法 | Integer::sum |
| 引用某个对象的方法 | list::add |
| 引用某个类的方法 | String::length |
| 引用构造方法 | HashMap::new |