MYSQL详解
下面介绍Mysql的详细学习内容及其方向。
注意规范
注意:所有的创建和删除操作尽量添加 IF EXISTS 语句进行判断,以免报错.
- `` :反引号,字段名必须使用它包裹;
- – info :单行注释,注意其–后必须空出一格才可以.
- /* info */ :多行注释.
- SQL关键语句大小写不敏感,但为了快速阅读以及排错,建议写小写.
- “” :引号,Default 默认语句和Comment 备注使用.
修改表
修改表名
ALTER TABLE 表名 RENAME AS 新表名 ;
ALTER TABLE teacher RENAME AS student ;
增加表字段
ALTER TABLE 表名 ADD 字段名 列属性 ;
ALTER TABLE teacher ADD age int(10) ;
修改表字段
ALTER TABLE 表名 MODIFY 字段名 新的列属性[] ; -- 只能修改字段列的属性以及约束,不能修改字段名
ALTER TABLE teacher MODIFY age int(12) ;
ALTER TABLE 表名 CHANGE 字段名 新字段名 新的列属性[] ; -- 字段名及列属性都能修改
ALTER TABLE teacher CHANGE age age1 int(13) ;
删除表字段
ALTER TABLE 表名 DROP 字段名 ;
ALTER TABLE teacher DROP age ;
MySql数据管理
外键(了解即可)
物理外键(不建议使用)
方法一:创建表时,增加约束.
不能单独删除被外键关系的表.
方法二:ALTER TABEL 表名 ADD CONSTRAINT ‘约束名’ FOREIGN KEY(‘列名’) REFERENCES ‘表名’(‘列名’)
DML语言(全部记住)
数据库意义:数据存储,数据管理
DML语言:数据操作语言
添加
-- 插入单行数据
INSERT INTO 表名 (字段1,字段2,字段3,...) VALUES (值1,值2,值3,...);
INSERT INTO 表名 VALUES (值1,值2,值3,...); -- 必须输入表所有字段值,并且位置一一对应,否则报错.
-- 插入多行数据
INSERT INTO 表名 (字段1,字段2,字段3,...) VALUES (值1,值2,值3,...),(值1,值2,值3,...),...
修改
UPDATE `表名` SET `字段` = `值` WHERE 条件...
UPDATE `表名` SET `字段` = `值`; -- 无条件时默认修改所有列数据
UPDATE `表名` SET `字段` = `值` , `字段` = `值` WHERE 条件... -- 修改多个字段值
删除
DELETE FROM 表名 WHERE 条件...
TRUNCATE 表名 -- 清空表所有数据
TRUNCATE删除所有数据时会将 自增字段 计数归零,而DELETE 则不会.
TRUNCATE删除所有数据不会影响事务.
DELETE删除问题: 重启数据库,在INNODB中,自增列从1开始(内存丢失).
在MyISAM中,自增列不会丢失计数.
DQL查询语言
DQL:Data query language -数据查询语言
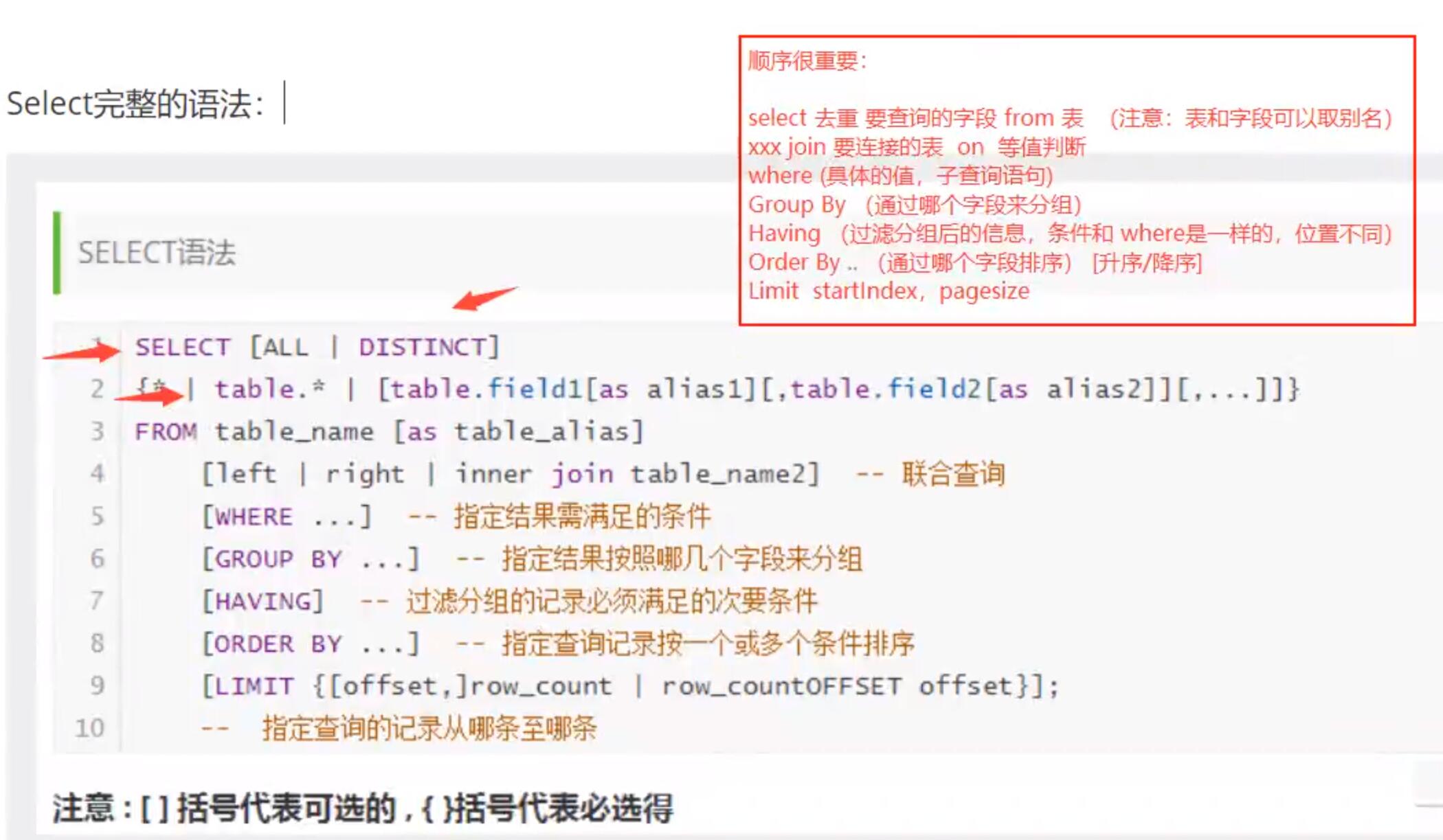
SELECT * FROM 表名; -- 查询表中所有字段数据
SELECT 字段1,字段2,字段3,... FROM 表名;
SELECT `字段1` AS 别名1,字段2 AS 别名2,字段3 AS 别名3,... FROM 表名; -- 以别名查询出来字段数据
-- 函数Concat(a,b)将a与b两结果想拼接
SELECT CONCAT('姓名',StudentName) AS 新名字 FROM student;
-- Distinct去重
SELECT DISTINCT 字段 FROM 表名;
联表查询JoinON详解
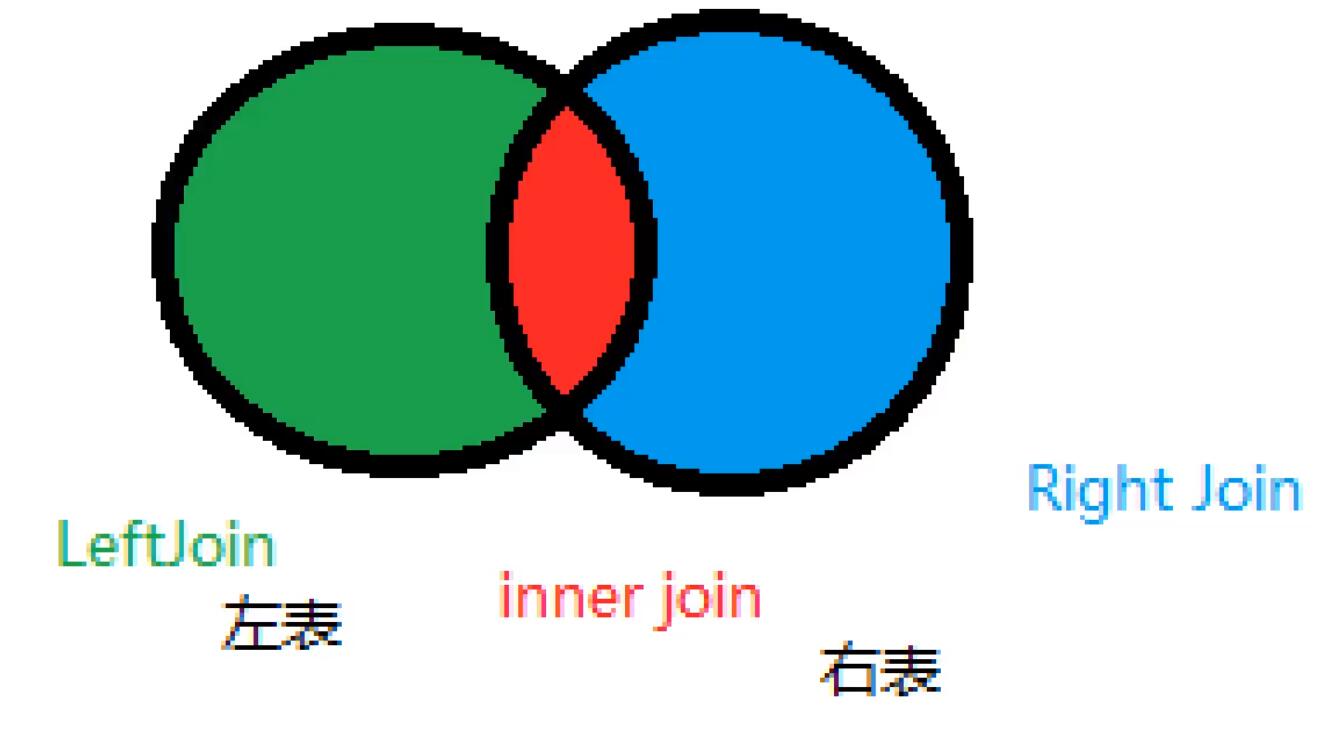
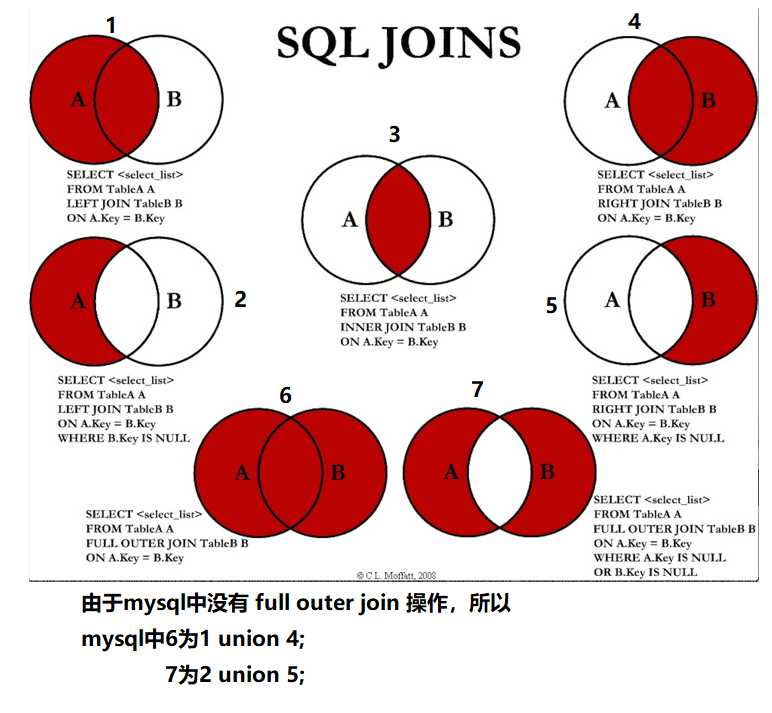
思路:
1.分析需求,分析查询的字段来自那些表,(连接查询)
2.确定使用那种连接查询? 7种
确定交叉点(这两表那些数据是相同的)
判断的条件: 表1 字段1=表2 字段2
-- join on 连接查询
-- where 等值查询
SELECT s.studentNo,studentName,subjectNo,studentResult
FROM student (AS)s -- AS 可以省略
INNER JOIN/ LEFT JOIN/ RIGHT JOIN result (AS)r
WHERE/ ON s.studentNo=r.studentNo
SELECT s.studentNo,studentName,subjectName,studentResult
FROM student (AS)s -- AS 可以省略
RIGHT JOIN result (AS)r
ON s.studentNo=r.studentNo
INNER JOIN subject sub
ON r.subjectNO=sub.subjectNO
-- 连接查询可以重叠查询
| 操作 | 描述 |
|---|---|
| inner join | 如果表中至少有一个匹配,返回所有值 |
| left join | 即使右表中没有匹配的数据,也会从左表中返回 |
| right join | 即使左表中没有匹配的数据,也会从右表中返回 |
自连接
自己的表和自己的表连接, 核心:一张表拆为两条一样的表
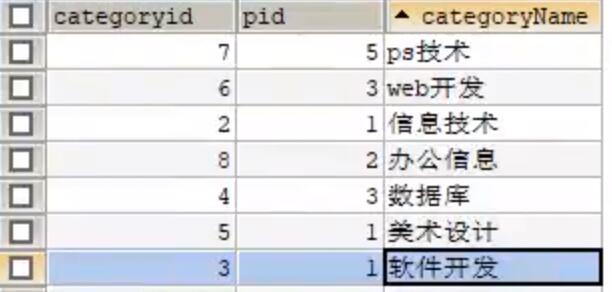
-- 把一张表看出两张一模一样的表
SELECT a.categoryName AS'父栏目',b.categoryName AS '子栏目'
FROM category AS a,category AS b
WHERE a.categoryid=b.pid

分页和排序
分页:limit 排序:order by
Order by:通过字段排序:升序 ASC ,降序 DESC
SELECT 字段1,字段2,...
FROM 表名
WHERE 条件
ORDER BY 字段 (ASC/ DESC)
Limit 起始值,显示个数 (起始值首项为0)
SELECT 字段1,字段2,...
FROM 表名
WHERE 条件
Limit 0,5 -- 从第一条数据开始,显示5条数据
– 设定每页显示5条数据
–第一页 limit 0,5 (1-1)*5
–第二页 limit 5,5 (2-1)*5
–第三页 limit 10,5 (3-1)*5
–第N页 limit (N-1)*PageSize,PageSize
–[PageSize:页面大小,(N-1)*PageSize:起始值,N:当前页]
子查询
常用函数
ABS(-8) –绝对值 CEILING(9.4) –向上取整 FLOOR(9.4) –向下取整
RAND() –返回一个0-1之间的随机数 CHAR_LENGTH(‘scarf’) –返回字符串的长度 CONCAT(‘2’,’3’) –拼接字符串
REPLACE(‘2333’,’23’,’41’) –替换指定字符串内容 SUBSTR(‘safer’,1,3) –返回指定位置字符串(字符串,截取位置,截取长度)
聚合函数及分组过滤
GROUP BY 字段:通过字段来分组
COUNT():查询表中记录条数
COUNT(字段) – 会忽略所有的NULL值
COUNT(*) – 不会忽略NULL值,本质 是计算行数
COUNT(1) – 不会忽略NULL值,本质是计算行数
SUM(字段):计算所有行总和
AVG(字段):计算所有行平均分
MAX(字段):查询所有行中最高分
MIN(字段):查询所有行中最低分
WHERE 条件中不能包含聚合函数.聚合函数过滤 需要使用 HAVING
SELECT SubjectName,AVG(studentResult) AS '平均分'
FROM result
GROUP BY SubjectNo
HAVING 平均分>80
Mysql事务
1.事务简介
(1)在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
(2)事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
(3)事务用来管理 insert,update,delete 语句。
(4)Mysql自动默认开启事务自动提交.
SET autocommit = 0 /* 关闭 */
SET autocommit = 1 /* 开启(默认) */
2.事务四大特征/原则
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部失败,不会只发生其中一个动作。
一致性:在事务开始结束前后数据结果要保证一定一致.
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,多个并发事务不会互相影响。
事务隔离分为不同级别:
- 脏读:指一个事务读取了另一个事务未提交的数据.
- 不可重复读:在一个事务读取数据时,多次读取结果不同.(不一定错误,只是场合不对)
- 幻读(虚读):在一个事务读取了别的事务插入的数据,导致前后读取不一致.
持久性:事务处理结束后的数据不会随外界原因而导致数据丢失,一旦事务提交不可逆。
3.MYSQL 事务处理
手动处理事务
0.关闭事务自动提交
SET autocommit = 0
1.事务开启
START TRANSACTION -- 标记一个事务的开始,从这之后的SQL语句都在一个事务内.
2.提交事务 :持久化 (成功的话)
COMMIT
3.回滚事务 :回到之前的样子(失败的话)
ROLLBACk
3.事务结束
SET TRANSACTION = 1
4.保存点
SAVEPOINT xxx1(保存点名) -- 设置一个叫xxx1的事务保存点
ROLLBACK TO SAVEPOINT xxx1(保存点名) -- 回滚到xxx1保存点
RELEASE SAVEPOINT xxx1(保存点名) -- 撤销xxx1保存点
索引
索引是帮助Mysql高效获取数据的数据结构.
但索引的缺点:会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
索引分类
主键索引 (PRIMARY KEY)
- 唯一标识,主键不可重复,只能有一个列为主键
唯一索引 (UNIQUE KEY)
- 避免重复的列出现,唯一索引可以重复,多个列可以标识为 唯一索引
常规索引 (KEY/INDEX)
- 默认的index,key关键字来设置
全文索引(FULL TEXT)
- 在特定的数据库才有,MyISAM
快速定位数据
索引使用
– 在创建表时给字段添加索引
– 创建完毕后,添加索引
SHOW INDEX FROM 表名 -- 显示表中的所有索引
ALTER TABLE 表名 ADD FULLTEXT/UNIQUE 索引名(字段名) -- 修改表结构,添加一个全文索引
CREATE INDEX/UNIQUE INDEX 索引名 ON 表名 (字段名) -- 在一个表中添加一个常规索引
/*在创建表时添加索引*/
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX/UNIQUE [索引名] (username(length)) -- 如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
);
DROP INDEX [索引名] ON 表名; -- 删除索引
-- 插入100万条数据
CREATE FUNCTION mock_date()
Returns INT
DELIMITER $$ -- 写函数之前必须写,标志
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i索引原则
- 索引不是越多越好,表中数据非常的时才考虑.
- 不要对进程变动数据加索引
- 小数据量的表不需要加索引
- 索引一般加载常用来查询的字段上!
索引的数据结构:
Hash 类型的索引
Btree :InnoDB默认的默认索引类型
简称B+树B树的每个节点对应innodb的一个page,page大小是固定的,一般设为 16k。其中非叶子节点只有键值,叶子节点包含完成数据。
权限管理和备份
用户管理
用户表: mysql.user表
本质:对这张表进行增删改查
CREATE USER 用户名 IDENTIFIED BY '密码' -- 创建一个默认用户
SET PASSWORD= PASSWORD('密码') -- 修改当前用户密码
SET PASSWORD FROM 用户名= PASSWORD('密码') -- 修改指定用户密码
RENAME USER 用户名 To 新用户名 -- 修改指定用户名
GRANT ALL PRIVILEGES ON *.* TO 用户名 -- 给指定用户授权所有权限(除了给别人授权)在所有数据库中所有表
SHOW GRANT FOR 用户名 -- 查看指定用户权限
REVOKE ALL PRIVILEGES ON *.* FROM 用户名 -- 撤销指定用户所有权限在所有数据库中所有表
DROP USER 用户名 -- 删除指定用户
Mysql备份
1.直接拷贝data文件夹下的物理文件
2.使用可视化工具手动导出
3.使用命令行导出 mysqldump 命令行
mysqldump -h`mysql地址` -u`用户名` -p`密码` 数据库名 表名 表2 表3 ... >物理磁盘位置:/文件名.sql(导出地址)
数据库三大范式
为什么需要数据库范式化?
信息重复
更新异常
插入异常
- 无法正常显示信息
删除异常
- 丢失有效信息
范式的英文名称是Nomal Form,它是英国人 E.F.Codd(关系数据库的老祖宗)在上个世纪70年代总结出来的,是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法。
第一范式(1NF)
原子性: 保证每列不可再分,主键不能为空,主键不能重复。
比如现需设计一个联系人数据库,现有(姓名,性别,电话) ,那么其中电话就得分为座机电话,手机两种。
所以最终联系人数据库结构就为(姓名,性别,家庭电话,公司电话)。
所以简而言之,第一范式就是无重复的列,且每个实体属性不能再分。在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
第二范式(2NF)
前提:满足第一范式
每张表必须含有且只能有一个主键。
且每张表只描述一个事情,对于有多个主键含义字段表进行拆分。
比如有一个订单表,结构为(订单编号,产品编号,订购日期,价格…),其中订单编号和产品编号都含有唯一主键含义,所以就需要拆分为两个表,订单表和产品表。
当然为了后续多表查询遍历,可以在订单表中进行保留产品编号作为查询条件。
第三范式(3NF)
前提:满足第一范式和第二范式
确保数据表中每列数据和主键直接相关,而非主键列(普通列)不能与另外非主键列(普通列)有依赖关联关系。
比如有一个订单表,存在(订单编号,订货日期,顾客编号,顾客姓名…)
其中订单编号为主键,而顾客编号与顾客姓名进行了依赖关联,所以根据第三范式,不得有非主键列的相互依赖关联关系,顾客姓名这列就得去除掉。
规范性和性能的问题:
关联查询的表不能成过三张表
- 考虑商业化需求和目标(成本,用户体验)数据库的性能更加重要
- 规范性能的问题的时候,需要适当考虑一下示范性
- 故意给某些表增加一些冗余的字段(从多表查询变单表查询)
- 故意增加一些计算列(大数据量降低为小数据量的查询:索引)
所以根据情况而设计数据库,不一定要求设计满足所有范式规范。